
Как ваш бизнес, управляемый ИИ, может извлечь выгоду из синтетических данных в 2025 году?
- Данные
- 23 ноября 2023 года
В этом возрасте, когда данные и ИИ управляются, тот, кто владеет большим количеством данных, имеет большой потенциал для впечатляющего бизнеса, заставить кого-то поручиться за них или играть в свои вредоносные игры. Хотя обмен данными с кем-то может показаться нормальным для персонализированного опыта, это также может вызвать проблемы с другой стороны из-за проблем с конфиденциальностью.
- Что, если вы можете поделиться данными с кем-либо, не беспокоясь о нарушении закона о конфиденциальности?
- Что, если вы действительно можете создать новый поток доходов, продавая свои данные кому-то, обеспечивая при этом самые высокие стандарты безопасности и конфиденциальности?
- Что, если вы действительно можете получить релевантные данные, которых нет у кого-то, и обучить свой ИИ?
Да, с помощью Synthetic Data вы все можете сделать это возможным!
По оценкам Gartner, почти все данные, которые будут использоваться в учебных проектах по ИИ и аналитике, будут генерироваться синтетическим путем, и это затмит использование реальных данных к 2030 году.
Согласно DataHorizzon Research, размер рынка синтетических данных, по прогнозам, достигнет 6,9 млрд долларов к 2032 году, при CAGR 37,5%.
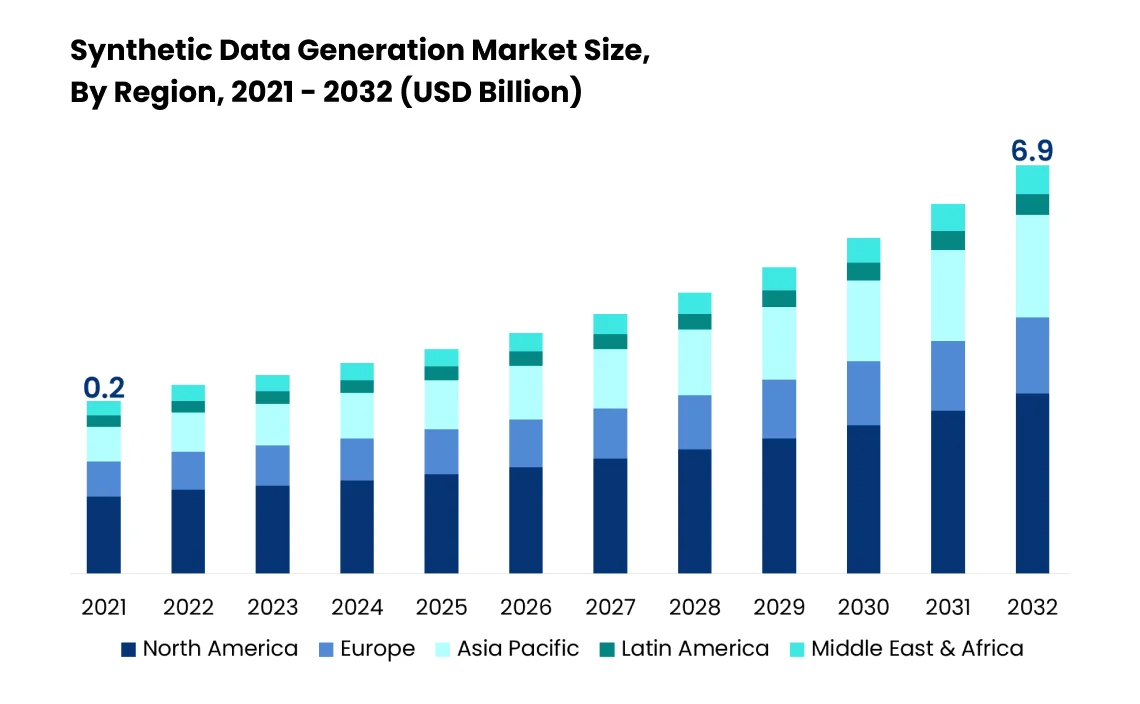
После просмотра этих цифр мы можем сказать, что эта концепция привлекла внимание к эволюции ИИ и играет ключевую роль в различных отраслях.
В этом блоге мы рассмотрели все, что вам нужно знать о синтетических моделях, от введения в них, их вариантов использования и преимуществ до того, как эффективно генерировать синтетические данные.
Итак, давайте погрузимся в океан синтетической генерации данных!
Что такое синтетические данные?
Синтетические данные — это компьютерные, искусственные данные, генерируемые с помощью алгоритмов, работающих на вводе реальных данных или вручную созданных данных, которые вы хотите заселить. Он предназначен для улучшения моделей ИИ, защиты конфиденциальных данных и смягчения предубеждений. Для более глубокого изучения, для генерации синтетических данных эксперты по данным используют статистические методы, машинное обучение (GAN-генерирующие состязательные сети, класс рамок машинного обучения) или комбинацию обоих.
Алгоритмы сначала анализируют данные обучения, а затем воспроизводят данные на основе своих статистических моделей, чтобы создать множество уникальных вариаций, имитирующих те же характеристики и прогностическую мощность, что и исходные данные.В то время как реальные данные генерируются реальными системами (такими как медицинские тесты или банковские транзакции), синтетические данные генерируются с использованием математических моделей или алгоритмов.
В отличие от реальных данных, которые имеют много положений безопасности, синтетические данные позволяют вам делиться ими с кем угодно, не раскрывая никакой конфиденциальной информации.
Синтетические данные могут быть получены в различных формах, таких как текст, изображение, видео и аудио, с множеством форматов представления.
Вы можете использовать синтетические данные для различных целей, включая обучение моделей ИИ, проверку моделей и тестирование новых продуктов и инструментов.
Какую ценность синтетические данные создают для вашего бизнеса?
Вы можете обнаружить, что эта концепция синтетического генерирования данных и моделирования является новой концепцией. Но, безусловно, в последующие годы она будет звучать довольно эффективно и будет принята многими предприятиями, занимающимися данными и ИИ, поскольку она предлагает следующие три преимущества «S»:
Безопасность: конфиденциальная защита информации
Например, когда вы делитесь реальными данными с кем-то, кто обучается на моделях ИИ / ML, какова гарантия того, что они не будут злоупотреблять этими данными, которые могут иметь чьи-то личные данные? Благодаря синтетическим данным вы можете избежать этих рисков безопасности, генерируя соответствующие данные, имитируя реальные и делясь ими с третьими лицами.
Скорость: быстрый доступ к данным
Вы хотите быстро обучить свои модели ИИ / ML, чтобы как можно скорее начать их работу, чтобы начать генерировать ценность для вашего бизнеса, но работа с данными в реальном времени может быть трудной задачей. Поскольку синтетические данные имеют дело с частями безопасности и конфиденциальности, они устраняют эту зависимость и освобождают вас от перекрестных проверочных случаев, чтобы попасть в положения, нарушающие правила (действуя как препятствия для достижения эффективности) и использует это время для укрепления вашей модели ML.
Кроме того, компании могут быстро обучать свои модели ML на наборах данных независимо от размера и длины наборов данных. Это косвенно приводит к достижению эффективности в обучении, тестировании и развертывании вашего решения ИИ на рынке.
Через это, Ученые данных и Инженеры ML Работа над вашим проектом ИИ даст вам больше уверенности на этапах разработки модели. С этой уверенностью они также помогут вам быстро продавать ваш продукт и быстрее генерировать ценность для бизнеса.
Шкала: пропускная способность для решения данных и проблем в масштабе
Если вы получаете лучшую безопасность и скорость для своего решения ИИ, то масштабирование его будет сопровождаться дополнительным подарком. Технически говоря, доступ к безопасности и скорости предлагает лучшую возможность анализировать данные в масштабе и, таким образом, решать больше проблем.
Это преимущество, предлагаемое синтетическими данными, может показаться более полезным для предприятий, в зависимости от текущих данных, генерируемых с помощью их продукта на основе ИИ, для масштабирования их возможностей ИИ и точности решения и обеспечения лучшего взаимодействия с пользователем и клиентами.
Каковы преимущества использования синтетических данных над реальными?
Сбор реальных данных из разных источников и в разных контекстах может быть процессом, разрушающим сознание. Например, для обучения автономных транспортных средств вы не можете полагаться на оригинальные данные; для этого требуется некоторое моделирование. Для этого вступают в игру синтетические данные. Кроме того, ниже приведены причины, по которым синтетические данные выигрывают, и, следовательно, вы должны принять следующее:
Вы можете создавать синтетические данные в соответствии с вашими потребностями.
Поскольку синтетические данные генерируются с помощью алгоритмов, основанных на моделировании, у них есть свои взлеты и падения. Повышенный эффект заключается в том, что вы контролируете, какие данные вы хотите генерировать в каком количестве, контролируя частоту событий, распределение объектов и т. Д.
Недостатком является то, что есть вероятность того, что синтетические данные пропустят крайние случаи, которые часто создаются в реальных наборах данных через сценарии реального взаимодействия. Однако этого можно избежать, создав гибридные наборы данных, комбинацию синтетических данных с помесью некоторых редких случаев реальных наборов данных. Кроме того, вы также можете манипулировать синтетическими наборами данных для более точного тестирования и обучения моделей ML.
Следовательно, все зависит от вас и вашего поставщика услуг синтетического моделирования данных, чтобы создать качество синтетических данных, которое лучше всего подходит для вашего решения ИИ.
Синтетические данные можно создать как мультиспектральные
Такие данные часто полезны для автомобильных и автотехнологических компаний, создающих автономные транспортные средства. Причина в уровне сложности раздражения невидимых данных.
Поэтому крупнейшие компании, разрабатывающие автономные транспортные средства, такие как Waymo Alphabet, Zoox Amazon, NVIDIA, General Motors Cruise и многие другие, используют сгенерированные синтетические данные LiDAR для простой маркировки данных и приложений инфракрасного или радиолокационного компьютерного зрения, чтобы повысить эффективность обучения своих технологий беспилотных автомобилей.
Синтетические данные помогают маркировать данные до того уровня, когда человеческий интеллект также иногда отстает в интерпретации изображений.
Перебор за предвзятые наборы данных
Когда требуется получить различные данные, обмениваясь одними и теми же контекстными значениями, но с различными характеристиками, в то время предлагается модель большого языка (LLM). Эта модель часто звучит эффективно при генерации различных вариаций синтетических данных, которые так же эффективны, как реальные версии данных, обучение ваших моделей ML.
Таким образом, вы можете подготовить свои модели ML в различных условиях для различных ситуаций, не позволяя им следовать предубеждениям, которым часто следуют их коллеги.
Поиск конкретных реальных данных может быть трудоемким
Мы все можем согласиться с тем, что поиск реальных данных для условий, которые вам нужны, может быть трудоемким и утомительным процессом из-за его редкости. Кроме того, они генерируются в очень достаточных количествах. И, конечно, вы не можете полагаться на меньшее количество данных для обучения вашей модели ИИ.
Следовательно, для измерения скорости и количества вы должны выбрать генеративные синтетические данные для обучения вашего ИИ различным сценариям и обеспечения надежной производительности для ваших клиентов.
Экономически эффективный, чем сбор реальных данных
Поскольку время сэкономлено на генерации синтетических данных, это уменьшает дополнительные усилия, связанные с получением данных в масштабе. Как наиболее эффективное преимущество, синтетические данные помогают нам смягчить проблемы конфиденциальности, устраняя необходимость в деидентификации данных и защите конфиденциальности, таким образом, связанные с этим затраты.
Маркировка реальных данных может быть головной болью для нас, поскольку у нас есть ограничение на название каждой географической и реальной собственности, в то время как синтетические данные часто генерируются с помощью меток, экономя дополнительное время и затраты, связанные с маркировкой данных.
Поскольку он генерируется алгоритмически, мы контролируем, с какого типа данных начать; следовательно, для устранения очистки данных, гармонизации и организации требуется сбор постданных.
Устранение проблем безопасности и нормативных ограничений
Теперь мы знаем, что синтетические данные широко известны тем, что они обеспечивают генерацию данных путем репликации всех статистических свойств реальных данных, игнорируя или не используя свойства, что вызывает обеспокоенность по поводу правил конфиденциальности.
В реальных данных, используемых для обучения ИИ / МО, часто трудно поддерживать конфиденциальность, обеспечивая ее полезность. Либо вы можете защитить конфиденциальность данных или обеспечить ее полезность, отказавшись от конфиденциальности. Короче говоря, чтобы получить одно значение, вы должны потерять другое.
Благодаря полученным результатам, с помощью синтетических данных вы можете обеспечить конфиденциальность и полезность данных. Вы можете делиться своими синтетическими данными с третьими лицами для их исследовательских и имитационных целей и даже в качестве инструмента монетизации.
Улучшение согласованности данных со скоростью
Реальные данные могут быть в различных формах, но при обучении ваших решений ИИ / ML необходимо единообразие и согласованность, что помогает достичь синтетических данных. Единообразие в синтетических наборах данных делает его более эффективным для наиболее точного анализа и моделирования.
Кроме того, на основе данных входов для статистических свойств эти наборы данных генерируются со скоростью с большей точностью.
Кроме того, простота процесса генерации синтетических данных помогает получить качество и количество данных за меньшее время и усилий без ущерба для качества данных.

Как генерировать синтетические данные?
Сначала нужно выяснить точный тип синтетических данных, которые вы хотите генерировать. Затем вам нужно проконсультироваться со специалистом по синтетическим данным, чтобы доработать технику синтетических данных на основе типа точности и формата, который вы хотите иметь. Вот популярные методы, широко используемые для создания синтетических наборов данных с точностью:
Генерация случайных данных
В отличие от других процессов, генерация случайных синтетических данных - это скорее общая концепция, которая не определяет конкретное распределение, ни какой-либо конкретный шаблон или предсказуемость. Это поможет создавать данные случайным образом в масштабе; однако некоторые шаблоны будут обнаруживаться и трудно предвидеть. Основываясь на его быстроте и масштабе, это часто лучше всего подходит для таких приложений, как моделирование, криптография, тестирование и многое другое.
Популярными методами генерации случайных чисел являются псевдослучайные генераторы чисел (PRNG), генераторы истинных случайных чисел (TRNG), аппаратные генераторы случайных чисел (HRNG) и многое другое.
Получение данных из распределения
Это похоже на генерацию случайных данных с небольшими различиями и использованием функций распределения вероятностей.
Однако это самый популярный метод, используемый учеными-данными и экспертами по ИИ/МЛ, в котором они выводят или просто выборочно выводят числа в масштабе, генерируя точки данных, следующие характеристикам определенного распределения вероятностей. Поскольку этот метод не извлекает информацию из реальных данных, он создает слабо связанные наборы данных на основе реальных данных.
Генеративные модели
Мы живем в эпоху, когда генеративные модели и ИИ становятся любимым инструментом каждого, и это самая передовая техника для генерации синтетических данных. Она также известна как неконтролируемое обучение, которое автоматически обнаруживает и изучает идеи и шаблоны, которые могут быть использованы для создания новых примеров, разделяющих те же значения статистики, как если бы оно обучалось на реальных данных.
Когда дело доходит до генеративных моделей, есть два способа их использования:
Генеративные состязательные сети (GAN): В этом процессе обучения имитируются данные, поступающие из двух сетей: генеративной сети, которая создает синтетические экземпляры данных и дискриминатора, который оценивает их подлинность. Благодаря этому процессу генератор учится производить все более и более реалистичные данные.
С каждой итерацией обучения он генерирует данные более точно и в той степени, в которой даже дискриминаторам трудно различать реальные и синтетические данные.Кроме того, GAN могут использоваться для генерации синтетических данных любого формата, включая изображение, текст и многое другое.
Большие языковые модели (LLM): Хотя это может показаться более простым, они являются наиболее мощными алгоритмами для генерации синтетических данных. Они обеспечивают генерацию текстов любой длины на основе обучения, облегченного на данных в масштабе.
Рекуррентные нейронные сети, такие как сети с длинной кратковременной памятью (LSTM) или Gradient-based Regularized Optimization (GRO), а также трансформаторы, такие как версии GPT OpenAI, двунаправленные представления кодера от трансформаторов (BERT), трансформатор передачи текста в текст (T5) и т. Д., Используются в качестве языковых моделей, которые могут одновременно смотреть в прошлое и будущее, чтобы генерировать синтетические данные без рекурсии данных.
Увеличение данных
Генерация синтетических данных после увеличения данных является наиболее популярной техникой в области обработки данных. наука о данных и машинное обучениеОн требует увеличения реальных данных и создания новых точек данных путем применения различных преобразований к таким. Он помогает масштабировать наборы данных, улучшить обобщение модели и устранить дисбаланс классов.
- Увеличение данных изображения: Такие медиафайлы могут быть дополнены применением методов, включая ротацию, перелистывание, масштабирование, обрезку, корректировку яркости и т. Д.
- Увеличение текстовых данных: Здесь NLP используется с такими методами, как замена синонимов, перефразирование или добавление случайного контента в текстовые данные.
- Аудио-дополнение данных: Это может быть сделано путем применения смещения шага, растяжения / сжатия времени, добавления фонового шума или просто с частотной модуляцией.
- Увеличение табличных данных: Эти структурированные данные могут быть дополнены дублированием и изменением существующих строк со случайным шумом или применением статистических операций к численным функциям.
- Данные по временным рядам: Этот тип синтетических данных создается путем повторного отбора проб, введения случайных флуктуаций или применения преобразования Фурье.
Вариационные автокодировщики (VAE)
Вариационный автокодер (VAE) — это тип глубокой нейронной системы, обученной объективной функцией, и также довольно популярен среди ученых-данных и экспертов по ИИ/МЛ для генерации синтетических данных. Некоторые эксперты также называют VAE «черным ящиком», неконтролируемым методом машинного обучения для генерации синтетических данных. В этом случае создаются новые точки данных, похожие на реальные данные, которые будут использоваться для учебных целей.
VAE состоит из сети энкодеров, которая отображает входные данные в вероятностное распределение в латентном пространстве, что обеспечивает непрерывное и структурированное представление данных. В процессе генерации VAEs пробует точки из латентного распределения пространства. Затем декодерная сеть берет отобранную точку и картирует обратно в пространство данных для генерации синтетических данных.
Как синтетические данные революционизируют различные отрасли?
Хотя это довольно популярный вариант использования, который заключается в обучении решениям AI / ML, вы можете использовать синтетические данные для различных приложений на основе вашего типа отрасли:
Здравоохранение
Отрасль здравоохранения является наиболее совместимой отраслью (по данным ВОЗ). Хипаа соответствие, где они должны обеспечить конфиденциальность данных пациентов (история болезни, текущее состояние здоровья, платежная информация и т. д.) по сравнению с любым другим.
Однако, согласно одному из исследований Accenture, около 18% работников здравоохранения готовы продавать конфиденциальные данные пациентов неавторизованным лицам всего за 500-1000 долларов.
Эта проблема требует принятия AI в здравоохранении организации различными способами для защиты конфиденциальной информации.
Кроме того, в медицинских исследованиях и процедурах лечения, специалисты HealthTech потребуют данных для продолжения своих исследований. Из-за проблем конфиденциальности и соблюдения HIPAA, может стать трудно обмениваться данными пациентов.
Затем синтетические данные становятся отличными для организаций здравоохранения для следующих целей:
- Создание и обмен деидентифицированными наборами данных для исследований, анализа и разработки программного обеспечения для здравоохранения на основе ИИ
- Моделирование данных пациентов, чтобы помочь медицинским работникам практиковать процедуры, диагностировать заболевания и повышать свои навыки
- Разработка индивидуальных планов лечения пациентов с редкими или специфическими симптомами
- Чтобы получить импульс на конфиденциальности-сохранение исследований
- Запускать фармацевтические симуляции и получать помощь в открытии лекарств
Финансы
Что, если мы поделимся вашими личными данными с любой третьей стороной? Вы позволите нам? Конечно нет! Вместо этого подайте на нас иск за нарушение ваших прав на конфиденциальность. И обучить вас AI-powered fintech решениеВы не хотите проходить через обширные реальные процессы сбора данных или попадать в судебные иски. Поэтому синтетические данные - это отличная помощь.
Среди прочего, вы можете использовать синтетические данные для следующих случаев использования:
- Обмен данными с другими исследовательскими группами финтеха для сотрудничества с отраслевыми инновациями
- Генерация синтетических данных через генеративные адвербиальные сети для обнаружения и предотвращения мошенничества
- Поддержка приложений управления финансовыми рисками
Кибербезопасность
Каждый день кибер-атакующие находят новые способы взлома нашей сети для их вредоносного геймплея. Чтобы остановить их, вам нужно обучить свою сеть, работающую на ИИ, чтобы узнать все возможные способы взлома, и для этого требуются учения по атаке.
Учитывая это, вы можете использовать синтетические данные для проведения интеллектуальных учений по мосту безопасности и повысить возможности обнаружения угроз брандмауэра.
Развлечения
Индустрия развлечений также может извлечь выгоду из синтетического генерирования данных, чтобы получить более продвинутый опыт генерации контента.
В действительности, «Властелин колец: Две башни» был первым кинематографическим сражением, которое было разработано с использованием передового программного обеспечения визуального эффекта с искусственным интеллектом под названием Massive, которое помогает быстро населить аудиторию, чтобы быть представленным в сцене с различным поведением и действиями.
Недвижимость
В индустрии недвижимости синтетические данные могут быть весьма полезны для программного обеспечения на основе планирования интерьера любого объекта недвижимости.
В одном из наших клиентских проектов, названном Passio.AI, мы получили возможность работать над тремя различными продуктами ИИ, и один из них — это разработка новых технологий. Краска.AIЭто позволяет пользователям практически увеличить цвет своих различных стен комнаты, чтобы идеально спланировать интерьер на стороне цвета.
При обучении модели ML мы столкнулись с проблемой, заставив ее узнать, какой объект рядом со стеной не является стеной, а другой сущностью, и при щелчке по стене он не должен красить этот объект.
В качестве решения мы использовали синтетические данные и движок Unity для создания различных вариаций изображений комнат с различными размещениями комнатных объектов, а также солнечного света и отражений в формах изображения RGB и семантической сегментации. С помощью этих синтетических данных на основе изображений мы можем достичь более 90% точности на выходе этого продукта ИИ.
Как MindInventory может помочь вам с синтетическим моделированием данных?
Спрос на данные в этой цифровой среде всегда будет расти. Если все организации и предприятия откроют двери для своих данных, но синтетическим способом, у вас будет очень светлое будущее для обучения вашего ИИ в следующей степени. Это, безусловно, породит экономику синтетических данных, которая определенно может быть использована для хорошего дела без какого-либо нарушения прав на конфиденциальность данных. Просто, чем больше доступа к данным, тем лучше интеллектуальные системы ИИ могут появиться с более быстрым временем выхода на рынок.
В этом блоге вы прошли через революцию, которую синтетические данные могут принести в каждую мыслимую отрасль. Поскольку это передовая наука о данных, чем раньше вы примете ее для своего преобразующего проекта ИИ вместе с предприятиями, основанными на ИИ, основанном на фортуне, тем больше преимуществ вы можете извлечь из нее и поднять свой бизнес на вершину.
Итак, чего вы ждете? В MindInventory мы позволяем клиентам Наймите Data Data Science и Специализированные инженеры ML найм тех, кто будет к вашим услугам и поможет вам превратить ваше видение в интеллектуальное цифровое решение.Подключитесь сегодня, чтобы узнать возможности, которые мы можем создать для вашего продвинутого ИТ-проекта с помощью нашего экспертного руководства Услуги по развитию ИИ/ML.
FAQs о синтетическом моделировании данных
Если мы увидим, что яркая сторона ИИ становится основной функцией, которой будут управлять люди в этом мире, видя в вероятном будущем, синтетические данные действительно занимают позицию в формировании ИИ - мы ожидаем, что это будет. В эту эпоху, когда многие прогнозисты ИИ, как полагают, исчерпали уникальные данные, синтетические данные могут стать лучом надежды, катализатором в создании хорошо обученных моделей, принося пользу многим областям исследований и разработок.
Как синтетические данные звучат как многообещающее решение для вашего бизнеса Развитие ИИ/ML С его точностью он также сопряжен с проблемами собственного уровня. Он может включать в себя создание данных, которые точно отражают сложность реального мира, обеспечение того, чтобы модели, обученные синтетическим данным, хорошо работали с реальными данными, генерируемые данные не раскрывают конфиденциальную информацию, должны быть хорошо обобщены в различных случаях использования, имеющие дело со сложной структурой данных и гарантирующие, что они не наследуют предвзятость исходных данных.
При создании синтетических данных вы должны учитывать увеличение потенциальных предубеждений, которые могут наследовать синтетические данные, риски повторной идентификации и конфиденциального воздействия данных, не использовать неправильное применение в контексте более строгих этических норм, не генерировать данные без получения согласия, все необходимые стандарты подотчетности и прозрачности, этические проблемы в приложениях, таких как технологии глубокой подделки, а не чрезмерно полагаться на синтетические данные.












